LogStory¶
LogStory is used to update timestamps in telemetry (i.e. logs) and then replay them into a Google Security Operations (SecOps) tenant. Each usecase tells an infosec story, a “Log Story”.
Usecases¶
The stories are organized as “usecases”, which always contain events and may contain entities, reference lists, and/or Yara-L 2.0 Detection Rules. Each usecase includes a ReadMe to describe its use.
Only the RULES_SEARCH_WORKSHOP is included with the PyPI package. Learning about and installing addition usecases is described in usecases.
Tip
It is strongly recommended to review each usecase before ingestion rather than importing them all at once.
Documentation¶
For comprehensive documentation on using Logstory:
CLI Reference - Complete command reference with all options and examples
Configuration - Detailed configuration guide for all environments
.env File Reference - Complete guide to .env file format and all supported variables
Local File System Sources - Using
file://URIs for Chronicle replay use cases and local development
Installation¶
Logstory has a command line interface (CLI), written in Python, that is most easily installed from the Python Package Index (PyPI):
$ pip install logstory
The logstory CLI interface uses command groups and subcommands with arguments like so:
logstory replay usecase RULES_SEARCH_WORKSHOP
These are explained in depth later in this doc.
Configuration¶
After the subcommand, Logstory uses Typer for modern CLI argument and option handling. You can provide configuration in several ways:
1. Command Line Options:
logstory replay usecase RULES_SEARCH_WORKSHOP \
--customer-id=01234567-0123-4321-abcd-01234567890a \
--credentials-path=/usr/local/google/home/dandye/.ssh/malachite-787fa7323a7d_bk_and_ing.json \
--timestamp-delta=1d
2. Environment Files (.env):
All commands support the --env-file option to load environment variables from a file:
# For usecases commands
logstory usecases list-available --env-file .env.prod
logstory usecases get MY_USECASE --env-file .env.dev
# For replay commands
logstory replay usecase RULES_SEARCH_WORKSHOP --env-file .env
# Auto-download and replay if usecase is missing
logstory replay usecase OKTA --get --env-file .env
# Or enable auto-download globally via environment
export LOGSTORY_AUTO_GET=true
logstory replay usecase OKTA --env-file .env
Tip
For complete .env file syntax, all supported variables, and example configurations, see the .env File Reference.
Usecase Sources¶
Logstory can source usecases from multiple sources using URI-style prefixes. Configure sources using the LOGSTORY_USECASES_BUCKETS environment variable:
# Single bucket (default)
export LOGSTORY_USECASES_BUCKETS=gs://logstory-usecases-20241216
# Multiple sources (comma-separated)
export LOGSTORY_USECASES_BUCKETS=gs://logstory-usecases-20241216,gs://my-custom-bucket,gs://team-bucket
# Mix GCS and local file system sources
export LOGSTORY_USECASES_BUCKETS=gs://logstory-usecases-20241216,file:///path/to/local/usecases
# Local file system only
export LOGSTORY_USECASES_BUCKETS=file:///path/to/chronicle/usecases
# Backward compatibility (bare bucket names auto-prefixed with gs://)
export LOGSTORY_USECASES_BUCKETS=logstory-usecases-20241216,my-custom-bucket
Supported Source Types:
gs://bucket-name: Google Cloud Storage bucketsfile://path: Local file system directoriesFuture support planned:
git@github.com:user/repo.git,s3://bucket-name
Authentication:
GCS public buckets: Accessed anonymously (no authentication required)
GCS private buckets: Requires
gcloud application-default logincredentialsLocal file system: No authentication required (uses file system permissions)
The system automatically tries authenticated access first, then falls back to anonymous access
URI-Style Prefixes:
Use
gs://prefix for explicit GCS bucket specificationUse
file://prefix for local file system directories (absolute paths required)Bare bucket names automatically treated as GCS buckets (backward compatibility)
Future Git support:
git@github.com:user/usecases.gitorhttps://github.com/user/usecases.git
Commands:
# List usecases from all configured sources
logstory usecases list-available
# Override source configuration for a single command
logstory usecases list-available --usecases-bucket gs://my-specific-bucket
# Download usecase (searches all configured sources)
logstory usecases get MY_USECASE
# Examples with different source types
logstory usecases list-available --usecases-bucket file:///path/to/local/usecases
logstory usecases get USECASE_NAME --usecases-bucket file:///path/to/local/usecases
# Future Git support (when supported)
logstory usecases list-available --usecases-bucket git@github.com:myorg/usecases.git
Migration from Pre-URI Configuration¶
If you’re upgrading from a version without URI-style prefixes:
Before:
export LOGSTORY_USECASES_BUCKETS=logstory-usecases-20241216,my-bucket
After (recommended):
# GCS buckets with explicit prefixes
export LOGSTORY_USECASES_BUCKETS=gs://logstory-usecases-20241216,gs://my-bucket
# Or mix with local file system
export LOGSTORY_USECASES_BUCKETS=gs://logstory-usecases-20241216,file:///path/to/local/usecases
Note: The old format still works (backward compatibility), but using explicit URI prefixes (gs://, file://) is recommended for clarity and future compatibility.
Tip
For advanced configuration scenarios, environment files, CI/CD integration, and troubleshooting, see the comprehensive Configuration Guide.
Customer ID¶
(Required) This is your Google SecOps tenant’s UUID4, which can be found at:
https://${code}.backstory.chronicle.security/settings/profile
Credentials Path)¶
(Required) The credentials provided use the Google Security Operations Ingestion API. This is NOT the newer RESTful v1alpha Ingestion API (yet, but that is future work).
Getting API authentication credentials
“Your Google Security Operations representative will provide you with a Google Developer Service Account Credential to enable the API client to communicate with the API.”[reference]
Timestamp BTS¶
(Optional, default=1d) Updating timestamps for security telemetry is tricky. The .log files in the usecases have timestamps in many formats and we need to update them all to be recent while simultaneously preserving the relative differences between them. For each usecase, LogStory determines the base timestamp “bts” for the first timestamp in the first logfile and all updates are relative to it.
The image below shows that original timestamps on 2023-06-23 (top two subplots) were updated to 2023-09-24, the relative differences between the three timestamps on the first line of the first log file before (top left) and the last line of the logfile (top right) are preserved both interline and intraline on the bottom two subplots. The usecase spans an interval of 5 minutes and 55 seconds both before and after updates.
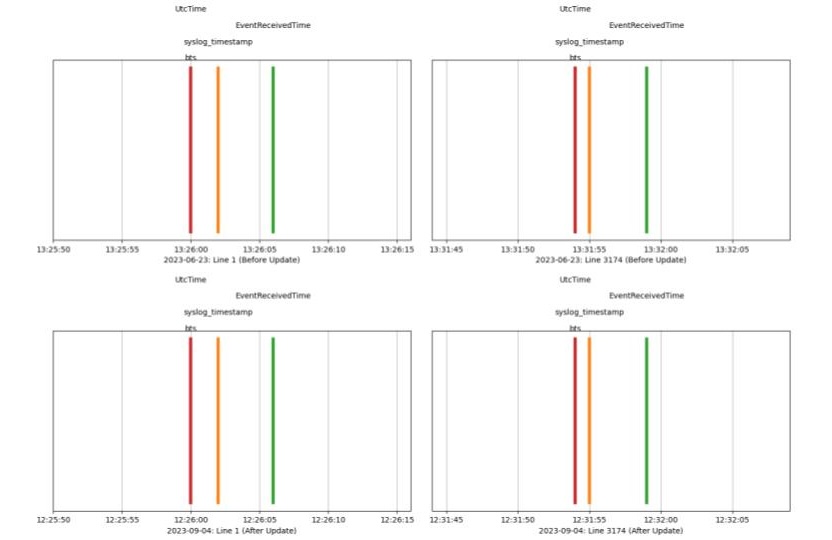
Timestamp Delta¶
When timestamp_delta is set to 0d (zero days), only year, month, and day are updated (to today) and the hours, minutes, seconds, and milliseconds are preserved. That hour may be in the future, so when timestamp_delta is set to 1d the year, month, and day are set to today minus 1 day and the hours, minutes, seconds, and milliseconds are preserved.
Tip
For best results, use a cron jobs to run the usecase daily at 12:01am with --timestamp-delta=1d.
You may also provide Nh for offsetting by the hour, which is mainly useful if you want to replay the same log file multiple times per day (and prevent deduplication). Likewise, Nm offsets by minutes. These can be combined. For example, on the day of writing (Dec 13, 2024)--timestamp-delta=1d1h1m changes an original timestamp from/to:
2021-12-01T13:37:42.123Z1
2024-12-12T12:36:42.123Z1
The hour and minute were each offset by -1 and the date is the date of execution -1.
Timestamp Configuration¶
LogStory uses YAML configuration files to define how timestamps are parsed and processed for each log type:
logtypes_entities_timestamps.yaml- Configuration for entity timestampslogtypes_events_timestamps.yaml- Configuration for event timestamps
Timestamp Entry Structure¶
Each log type defines timestamps with the following fields:
Required fields:
name: String identifier for the timestamp fieldpattern: Regular expression to match the timestampepoch: Boolean indicating timestamp format (truefor Unix epoch,falsefor formatted dates)group: Integer specifying which regex group contains the timestamp
Optional fields:
base_time: Boolean marking the primary timestamp (exactly one per log type)dateformat: Format string for non-epoch timestamps (required whenepoch: false)
Epoch vs Formatted Timestamps¶
LogStory supports two timestamp formats:
Unix Epoch Timestamps (epoch: true):
- name: event_time
base_time: true
epoch: true
group: 2
pattern: '(\s*?)(\d{10})(.\d+\s*)'
Formatted Timestamps (epoch: false):
- name: gcp_timestamp
base_time: true
epoch: false
dateformat: '%Y-%m-%dT%H:%M:%S'
group: 2
pattern: '("timestamp":\s*"?)(\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2})'
Configuration Validation¶
LogStory automatically validates timestamp configurations at runtime to ensure:
Each log type has exactly one
base_time: truetimestampAll required fields are present with correct data types
Epoch and dateformat fields are logically consistent:
epoch: truetimestamps should not havedateformatfieldsepoch: falsetimestamps must havedateformatfields
All timestamps follow consistent naming and structure patterns
If configuration validation fails, LogStory will provide clear error messages indicating the specific log type, timestamp, and issue found.
Command Structure¶
Logstory uses a modern CLI structure with command groups. You can replay specific logtypes like this:
logstory replay logtype RULES_SEARCH_WORKSHOP POWERSHELL \
--customer-id=01234567-0123-4321-abcd-01234567890a \
--credentials-path=/path/to/credentials.json
That updates timestamps and uploads from a single logfile in a single usecase. The following updates timestamps and uploads only entities (rather than events):
logstory replay logtype RULES_SEARCH_WORKSHOP POWERSHELL \
--customer-id=01234567-0123-4321-abcd-01234567890a \
--credentials-path=/path/to/credentials.json \
--timestamp-delta=0d \
--entities
You can increase verbosity by prepending the python log level:
PYTHONLOGLEVEL=DEBUG logstory replay usecase RULES_SEARCH_WORKSHOP \
--customer-id=01234567-0123-4321-abcd-01234567890a \
--credentials-path=/path/to/credentials.json \
--timestamp-delta=0d
For more usage, see logstory --help
Usecases¶
Usecases are meant to be self-describing, so check out the metadata in each one.
Tip
It is strongly recommended to review each usecase before ingestion rather than importing them all at once.
As shown in the ReadMe for the Rules Search Workshop,
If your usecases were distributed via PyPI (rather than git clone), they will be installed in <venv>/site-packages/logstory/usecases
You can find the absolute path to that usecase dir with:
python -c 'import os; import logstory; print(os.path.split(logstory.__file__)[0])'
/usr/local/google/home/dandye/miniconda3/envs/venv/lib/python3.13/site-packages/logstory
Adding more usecases¶
We’ve chosen to distribute only a small subset of the available usecases. Should you choose to add more, you should read the metadata and understand the purpose of each one before adding them.
For the PyPI installed package, simply curl the new usecase into the <venv>/site-packages/logstory/usecases directory.
For example, first review the ReadMe for the EDR Workshop usecase: https://storage.googleapis.com/logstory-usecases-20241216/EDR_WORKSHOP/EDR_WORKSHOP.md
Then download the usecase into that dir. For example:
gcloud storage rsync --recursive \
gs://logstory-usecases-20241216/EDR_WORKSHOP \
~/miniconda3/envs/pkg101_20241212_0453/lib/python3.13/site-packages/logstory/usecases/
To make that easier:
❯ logstory usecases list-available
Available usecases in source 'gs://logstory-usecases-20241216':
- EDR_WORKSHOP
- RULES_SEARCH_WORKSHOP
For multiple sources:
❯ export LOGSTORY_USECASES_BUCKETS=gs://logstory-usecases-20241216,gs://my-private-bucket
❯ logstory usecases list-available
Available usecases in source 'gs://logstory-usecases-20241216':
- EDR_WORKSHOP
- RULES_SEARCH_WORKSHOP
Available usecases in source 'gs://my-private-bucket':
- CUSTOM_USECASE
- TEAM_ANALYSIS
All available usecases: CUSTOM_USECASE, EDR_WORKSHOP, RULES_SEARCH_WORKSHOP, TEAM_ANALYSIS
❯ logstory usecases get EDR_WORKSHOP
Downloading usecase 'EDR_WORKSHOP' from source 'gs://logstory-usecases-20241216'
Downloading EDR_WORKSHOP/EDR_WORKSHOP.md to [redacted]/logstory/usecases/EDR_WORKSHOP/EDR_WORKSHOP.md
Downloading EDR_WORKSHOP/EVENTS/CS_DETECTS.log to [redacted]/logstory/src/logstory/usecases/EDR_WORKSHOP/EVENTS/CS_DETECTS.log
Downloading EDR_WORKSHOP/EVENTS/CS_EDR.log to [redacted]/logstory/src/logstory/usecases/EDR_WORKSHOP/EVENTS/CS_EDR.log
Downloading EDR_WORKSHOP/EVENTS/WINDOWS_SYSMON.log to [redacted]/logstory/src/logstory/usecases/EDR_WORKSHOP/EVENTS/WINDOWS_SYSMON.log
❯ logstory usecases list-installed
#
# EDR_WORKSHOP
#
...
Contributing¶
Interested in contributing? Check out the contributing guidelines. Please note that this project is released with a Code of Conduct. By contributing to this project, you agree to abide by its terms.
For detailed development and release documentation, see Development Documentation.
License¶
logstory was created by Google Cloud Security. It is licensed under the terms of the Apache License 2.0 license.
Development and re-building for publication on PyPI¶
git clone git@gitlab.com:google-cloud-ce/googlers/dandye/logstory.git
# Edit, edit, edit...
make build
# ToDo: pub to PyPI command
Testing¶
LogStory includes comprehensive validation tests for timestamp configurations:
# Run YAML validation tests
cd tests/
python test_yaml.py
The test suite validates all timestamp configurations in both entities and events files, ensuring:
Proper field structure and data types
Logical consistency between epoch and dateformat fields
Required field presence
Base time configuration correctness
All 55 log types across both configuration files are automatically tested for compliance with LogStory’s timestamp standards.
GCP Cloud Run Services¶
The project deploys to GCP Cloud Run as containerized services using Docker. This includes:
Containerized services for loading Entities and Events on 3 day and 24 hour schedules
Cloud Scheduler for triggering the services
GCP Cloud Storage bucket for the usecases
…
Prerequisites¶
Note
For detailed Cloud Run deployment instructions, see the Cloud Run Deployment Workflow guide.
Chronicle (Malachite) Google Cloud project configuration¶
The ingestion API used by LogStory is the Google Security Operations Ingestion API.
See also
Reference documentation for the Google Security Operations Ingestion API
Note
Your Google Security Operations representative will provide you with a Google Developer Service Account Credential to enable the API client to communicate with the API.
A Service Account is required in the
malachite-gglxxxxGoogle Cloud project for your Chronicle tenant. Create a new Service Account if needed.The Service Account needs the
Malachite Ingestion Collectorrole assigned to it in order to forward events to Chronicle.If you want to use Logstory’s sample rules with Chronicle, the service account also needs the
Backstory Rules Engine API Userrole.
Google Cloud project configuration¶
Authenticate to the Google Cloud project that is bound to your Chronicle tenant.
gcloud auth login
PROJECT_ID=your_project_id_here
gcloud config set project $PROJECT_ID
The Cloud Run deployment uses the default compute service account and Makefile targets for simplified deployment.
Enable the Google APIs in your project that are required to run Logstory.
gcloud services enable cloudresourcemanager.googleapis.com
gcloud services enable secretmanager.googleapis.com
gcloud services enable iam.googleapis.com
gcloud services enable run.googleapis.com
gcloud services enable cloudscheduler.googleapis.com
gcloud services enable artifactregistry.googleapis.com
gcloud services enable cloudbuild.googleapis.com
Configuration¶
For complete Cloud Run deployment instructions including environment setup, service account configuration, and deployment commands, see the Cloud Run Deployment Workflow guide.
Quick start using Makefile targets:
# Set required environment variables
export LOGSTORY_PROJECT_ID=your-gcp-project-id
export LOGSTORY_CUSTOMER_ID=your-chronicle-customer-uuid
export LOGSTORY_API_TYPE=rest # or 'legacy'
# Deploy to Cloud Run
make enable-apis
make create-secret CREDENTIALS_FILE=/path/to/credentials.json
make setup-permissions
make deploy-cloudrun-job
make schedule-cloudrun-all
Deployment¶
The project now deploys using Makefile targets instead of Terraform:
# Deploy the Cloud Run job and set up schedulers
make deploy-cloudrun-job
make schedule-cloudrun-all
# Check deployment status
make cloudrun-status
Navigate to the Cloud Run and Cloud Scheduler pages in the Google Cloud console and verify that the Logstory artifacts were created.
Cloud Schedulers¶
Logstory deploys a number of different Cloud Schedulers. Some data is ingested every 24hours and others every 3 days. If you want to ingest data immediately, you can force a run of the Cloud Scheduler job manually. However, we suggest you to run the logs in a specific order, first run the entities and after couple of hours, run the events.
Sample detection rules are included within individual usecases under their respective RULES subdirectories.
Cleanup¶
Run
make delete-cloudrun-allto remove all Cloud Run services, jobs, and schedulersDelete the rules created in your Chronicle SIEM using Delete Rule API